 Garanzia di Download Sicuro, zero malware
Garanzia di Download Sicuro, zero malware


Se sei qualcuno che lavora in campi che richiedono trascrizioni veloci e accurate, integrare apis vocal-to-testo nel tuo flusso di lavoro deve essere quello di cui hai bisogno. Grazie a questo apis, molti di questi apis forniscono un'opzione gratuita, in modo da poterli usare per semplificare il processo di trascrizione senza stringere il budget.
Per risolverli, abbiamo compilato un elenco diMiglior apis libera di parola al testoDisponibili, insieme alle loro caratteristiche chiave, limiti e come integrarli nei tuoi progetti. Anche se scopri che queste opzioni non soddisfano le tue esigenze, forniamo anche raccomandazioni alternative che potrebbero essere più adatte alle tue esigenze.

In questo articolo
Parte 1. Miglior API libera di parola a testo per trascrizione audio
Con la crescente domanda di trascrizione audio in vari settori come la creazione di contenuti, l'istruzione e le imprese, una domanda comune che molti utenti pongono è: "quali sono alcuni apis gratuiti o servizi online per la conversione vocale in testo?"
L'apis vocal-to-testo è essenziale per gli sviluppatori per integrare la funzionalità vocal-to-testo nelle loro applicazioni. In risposta a questa necessità, esaminiamo una panoramica approfondita delle principali apis libera di parola a testo disponibili oggi. Questi includono Google Cloud speed-to-text, Microsoft Azure Speech Service, Speechmatics, assembly, e aws transcribe.
1. Google Cloud speech to text API
L'API di voce a testo di Google cloud fa parte della suite di Google cloud, progettata per convertire l'audio in trascrizioni di testo accurate. Con apis facile da usare, gli sviluppatori possono integrare le funzionalità di riconoscimento vocale nelle loro applicazioni. Per utilizzare gratuitamente questo appi di voce a testo, Google offre agli utenti 60 minuti di trascrizione gratuita. I nuovi utenti possono anche esplorare voce a testo e altri prodotti cloud di Google con fino a $300 in crediti gratuiti.
Caratteristiche chiave:
- Modello vocale avanzato di Google Cloud, addestrato su milioni di ore di dati audio e miliardi di frasi di testo
- Offre supporto per 125 lingue e varianti, rendendolo adatto per una base di utenti diversificata
- Fornisce una selezione di modelli addestrati su misura per casi d'uso specifici, tra cui il controllo vocale, la trascrizione delle chiamate telefoniche e la trascrizione video
- Utilizza tecniche di adattamento del modello per migliorare l'accuratezza delle parole usate frequentemente, espandere il vocabolario per la trascrizione e migliorare le prestazioni in ambienti audio rumorosi
Limitazioni:
- Il livello libero permette solo 60 minuti di trascrizione al mese. Potrebbe non essere sufficiente per progetti più grandi o frequenti esigenze di trascrizione
- Meno conveniente per coloro che non hanno familiarità con i servizi cloud di Google. è necessario caricare file audio in un bucket di archiviazione cloud di Google prima della trascrizione
- Funzionalità di personalizzazione avanzate potrebbero non essere completamente accessibili nella versione gratuita
Ideale per:Basse esigenze di trascrizione, come piccole imprese o freelancer che trascrivono brevi interviste, podcast o incontri.
2. Microsoft Azure Speech API
L'API di speech di Microsoft azure fa parte della suite di servizi cognitivi di azure. Per usarlo gratuitamente, l'API di speech di Microsoft Azure offre un livello gratuito con un utilizzo limitato. Il livello è ideale per piccoli progetti, test e scopi di apprendimento. Include funzionalità come trascrizione in tempo reale e modelli vocali personalizzabili. Puoi visitare Microsoft AzurePagina dei prezziPer maggiori dettagli.
Caratteristiche chiave
- Recuperare i log per ciascun endpoint su richiesta per quel specifico endpoint
- Accedere al manifesto dei modelli creati per impostare contenitori locali
- Caricare dati da account di archiviazione azure utilizzando una firma di accesso condiviso(SAS) URI
- Utilizzare i propri account di archiviazione per gestire log, file di trascrizione e altri dati
- Trascrivere file audio in batch da più url o un contenitore azure
Le limitazioni
- Il livello gratuito permette di ospitare solo un modello vocale personalizzato al mese e solo 5 ore audio gratuite al mese
- Mentre la trascrizione di azure è generalmente accurata, occasionalmente fatica con l'ortografia corretta delle parole
- La configurazione iniziale dell'API azure speech può essere complessa
Ideale per:Settori come l'assistenza sanitaria, la finanza o i servizi legali dove la terminologia specializzata è frequentemente utilizzata.
3. Parola di parola
Speechmatics offre un API di lingua a testo con un generoso piano gratuito, fornendo agli utenti 8 ore di trascrizione al mese. Questo piano include 4 ore per l'elaborazione batch e ulteriori 4 ore per la trascrizione in tempo reale. Progettato per la flessibilità, speechmatics si adatta a varie applicazioni, dalla produzione multimediale al servizio clienti. è possibile sfruttare i suoi algoritmi avanzati di apprendimento automatico per ottenere risultati elevati e affidabili, anche in ambienti audio impegnativi.
Caratteristiche chiave
- Supporta circa 50 lingue, offrendo una vasta copertura per vari accenti e dialetti.
- L'API fornisce trascrizione in tempo reale con una latenza inferiore a un secondo
- Identificare automaticamente la lingua parlata
- Ogni parola nella trascrizione è accompagnata da un timestamp preciso
- Esporta le trascrizioni come sottotitoli srt
Le limitazioni
- Configurazione comporta la configurazione di interfacce personalizzate, rendendolo più adatto per le imprese con risorse tecniche.
- Non adatto per piccole imprese o progetti a causa di requisiti tecnici
Ideale per:Le esigenze di trascrizione aziendale su larga scala.
4. L'assemblea
Assembly offre modelli vocali guidati da ai tramite un'API. Se sei un nuovo utente, riceverai un credito gratuito di $50 per iniziare. Questa API supporta varie attività di dati vocali. Includono la diarizzazione degli oratori, il rilevamento degli argomenti, l'analisi dei sentimenti e la sintesi del testo. Ci sono due opzioni di lingua a testo disponibili: "migliore" per un'elevata precisione e"Nano"per una trascrizione economica.
Caratteristiche chiave
- Diarizzazione degli altoparlanti per aiutare a identificare e separare diversi altoparlanti in una registrazione audio
- Ortografia personalizzata e vocabolario dove è possibile inserire parole personalizzate o terminologia specializzata per una trascrizione accurata
- Censura automaticamente il linguaggio inappropriato e applica la corretta punteggiatura e involucro per una più facile leggibilità
Le limitazioni
- La piattaforma offre meno lingue rispetto ad alcuni concorrenti
- Bug e problemi occasionali possono richiedere tempo per essere risolti o risolti
- Lo strumento spesso difficile con l'accuratezza della trascrizione quando l'audio presenta rumori di fondo significativi o disturbi
Ideale per:Trascrivere incontri, interviste o podcast che coinvolgono più oratori.
5. Trascrizione aws
Amazon Transcribe, parte di aws, permette ai nuovi utenti di trascrivere un'ora gratuita ogni mese durante il loro primo anno. Questo servizio permette agli utenti di convertire audio in testo per varie esigenze, anche se richiede file audio per essere memorizzati in amazon s3.
Caratteristiche chiave
- Opzioni di punteggiamento e formattazione
- Vocabolario personalizzato per termini specifici del settore
- Identificazione multi-altoparlante
- Trascrive in testo i flussi audio dal vivo o il discorso pre-registrato
Le limitazioni
- Richiede archiviazione audio in Amazon s3
- Possono mancare parole specifiche, in particolare sostantivi propri o entità nominate (NER)
Ideale per:Le imprese che necessitano di trascrizione automatica per riunioni, media o assistenza clienti
Parte 2. Come iniziare con l'integrazione di API linguaggio a testo
Per iniziare con l'integrazione di API vocal-totext, ogni servizio di solito fornisce documentazione e risorse dettagliate per guidare gli sviluppatori attraverso il processo di impostazione. Di solito inizierai creando un account con il provider. Quindi, generare una chiave api che concede accesso al servizio.
Come dimostrazione, uno dei più popolari apis di riconoscimento vocale, Google Cloud speed-to-text, fornisce Google Cloud speed-to-text API documentazioneQui...Il processo comporta diverse fasi chiave:
- Creare un progetto cloud di Google:Iscriviti per un account google cloud e creare un nuovo progetto nella console google cloud. Questo progetto gestirà le risorse relative all'API.
- Abilita l'API di lingua a testo:Navigare alla sezione API & Servizi, cercare l'API di lingua a testo e abilitarla per il tuo progetto.
- Generare credenziali API:Creare un account di servizio e generare una chiave api, che userai per autenticare le richieste. Scaricare il file chiave(di solito in formato json) per memorizzare le tue credenziali.
- Imposta la libreria client:Installare le librerie client necessarie (come python, Java o node.js) per interagire programmaticamente con l'api. Le librerie client semplificano la realizzazione di richieste API e la gestione delle risposte.
- Scrivere codice per trascrivere audio:Utilizzare la chiave api e la libreria client per scrivere codice che converte l'audio in testo inviando dati audio ai server di Google cloud per l'elaborazione.
Guarda il tutorial completo qui su come integrare Google cloud libero spedizione-to-text API nella tua app.
Parte 3. Migliore soluzione per utilizzare il linguaggio in testo senza integrazione API
Non ogni utente o azienda deve integrare apis, poiché la configurazione può essere complessa, richiede tempo e talvolta non necessaria per progetti più piccoli o singoli utenti. Invece, c'è un altro modo di convertire il discorso in testo senza l'integrazione API. Una di queste opzioni èWondershare Filmora Parola in testoLa funzione.
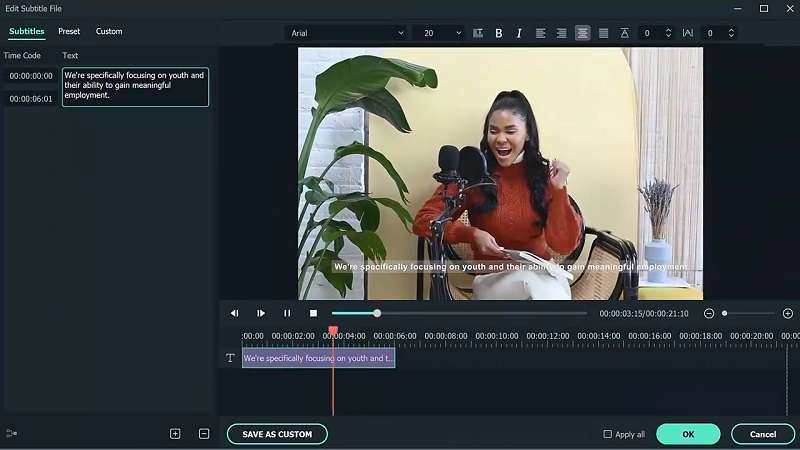
Funzione di lingua a testo di Filmora
Filmoraè uno strumento di editing video popolare che viene dotato di una funzione vocale a testo integrata. è possibile utilizzarlo per convertire parole parlate in file audio o video direttamente in testo. Questa funzione è una soluzione senza problemi per generare rapidamente sottotitoli, sottotitoli o trascrizioni. Non devi preoccuparti di trascrizione manuale o di configurazioni complesse: il processo è completamente automatizzato.
Inoltre, se stai lavorando su progetti multilingue o hai bisogno di trascrivere contenuti in lingue diverse, il linguaggio linguistico a testo di Filmora supporta anche più lingue. Includono inglese, francese, spagnolo, indonesiano, Hindi, giapponese, e altro ancora.
Quando scegliere la funzione lingue-to-testo di filmora invece dell'integrazione API?
- Utenti non tecnici:Se non hai un background tecnico o un team di sviluppo, l'interfaccia di Filmora facile da usare elimina la necessità di integrazione API.
- Progetti di trasformazione rapida:Quando è necessario trascrivere rapidamente i contenuti per sottotitoli, sottotitoli o progetti video brevi, il processo completamente automatizzato di Filmora risparmia tempo rispetto alla configurazione manuale dei servizi API.
- Lavorare con contenuti video:Poiché filmora combina la funzionalità di modifica video e parola a testo in una sola piattaforma, è possibile applicare il testo trascritto direttamente ai tuoi progetti video per sottotitoli, sottotitoli o trascrizioni senza passare tra strumenti.
Passo dopo passo utilizzando il linguaggio a testo con filmora
Passo 1:Apri filmora e importi il tuo file audio
Assicurati di avere l'ultima versione di filmora installata sul computer. Quindi, iniziare avviando filmora e selezionandoNuovo progettoPer creare un nuovo progetto.
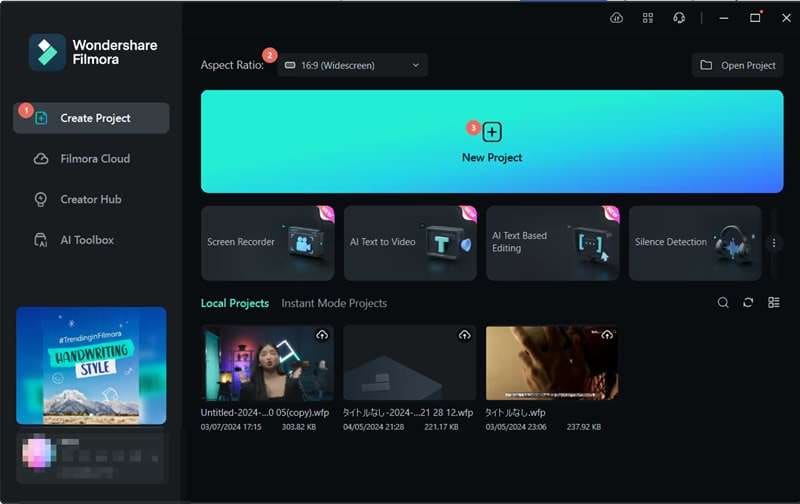
Per caricare il file audio, fare clic suL'importazioneE scegliere il file dal computer.
Passo 2:Accedi allo strumento linguaggio a testo
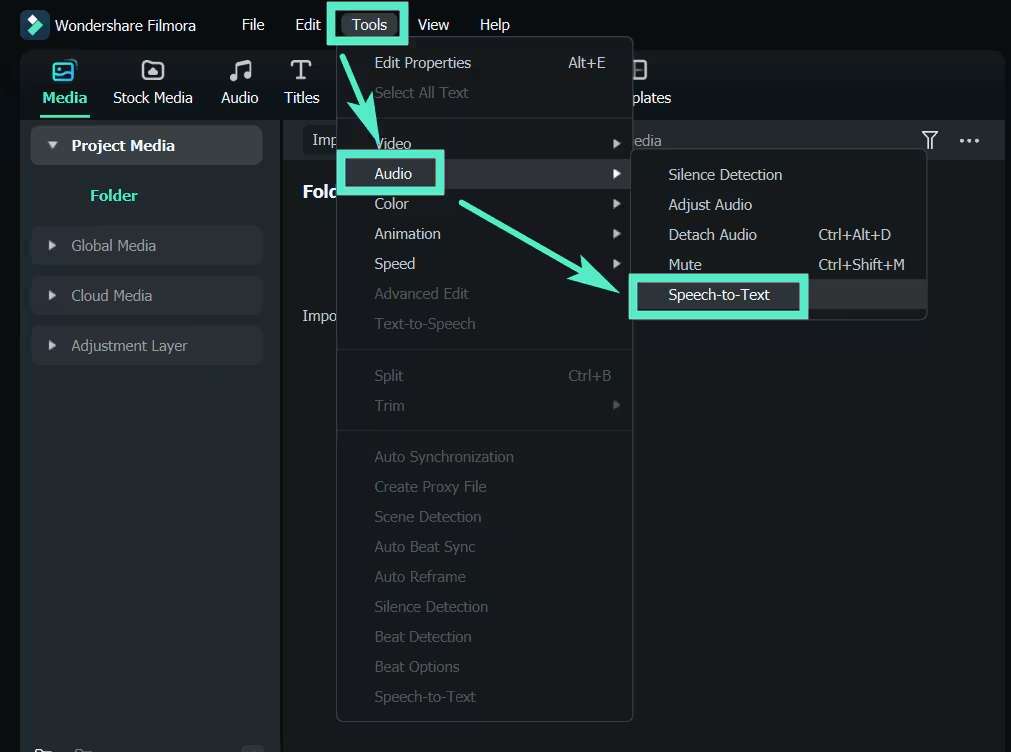
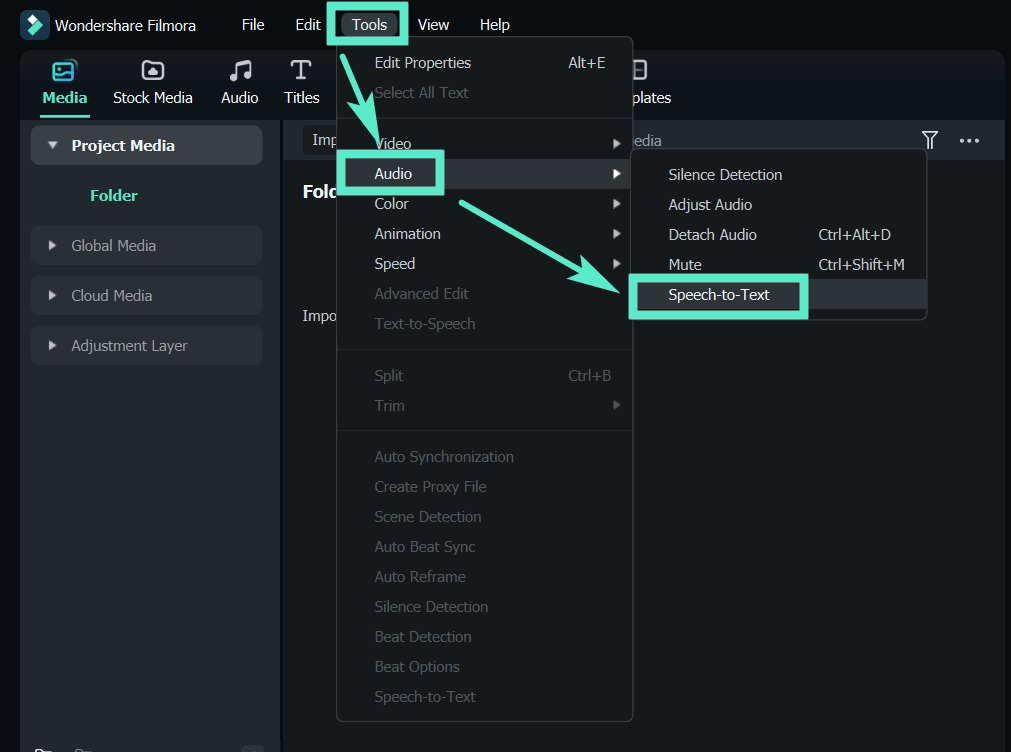
Una volta importato il file audio, trascinarlo nella timeline. Per attivare lo strumento di conversione vocale in testo, selezionare la traccia audio sulla timeline. Allora, vai aStrumenti > Audio > lingua a testo.
Passo 3:Imposta le preferenze di trascrizione
Una finestra di configurazione perFunzione di lingua a testoApparirà. Qui, è possibile selezionare la lingua del file audio che si sta trascrivendo. Se non hai bisogno di tradurre il discorso, selezionare ilNessuna traduzione"Opzione sotto"Lingua da tradurre in"Sezione.
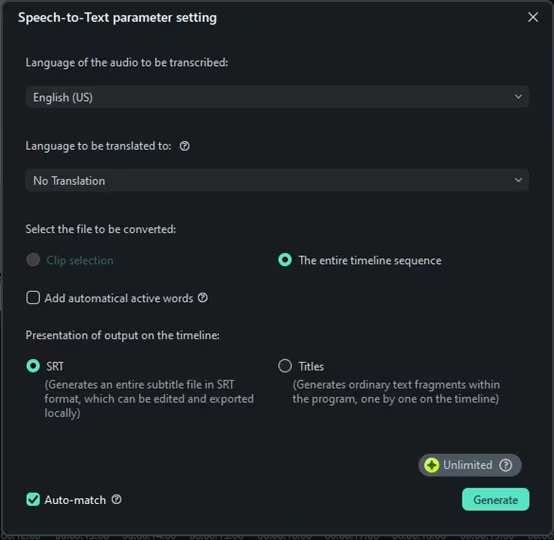
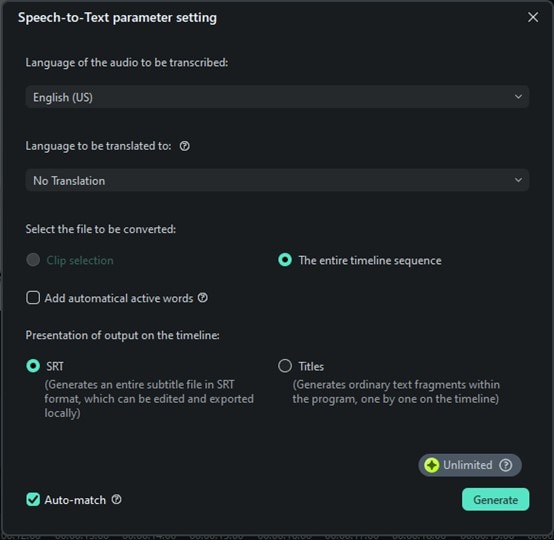
è possibile decidere se trascrivere solo la clip audio selezionata o l'intera timeline. Scegliere il formato di output come file srt.
Passo 4:Inizia a trascrivere l'audio
Una volta che tutte le impostazioni sono in atto, fare clic suGenerare ilPulsante. Filmora elaborerà l'audio e creerà la trascrizione. Una volta fatto, il file di trascrizione sarà disponibile nelI MediaLa scheda.
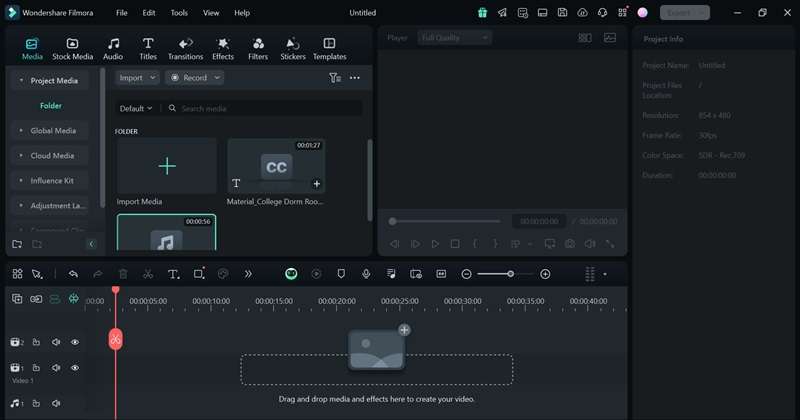
Passo 5:Modifica la trascrizione
Se è necessario regolare la trascrizione, fare doppio clic sul file di trascrizione generato per aprire l'interfaccia di modifica. Qui, è possibile rivedere il testo e apportare le correzioni necessarie.
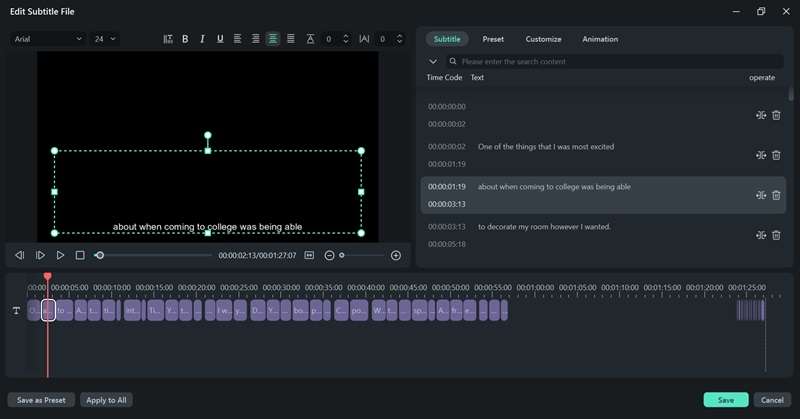
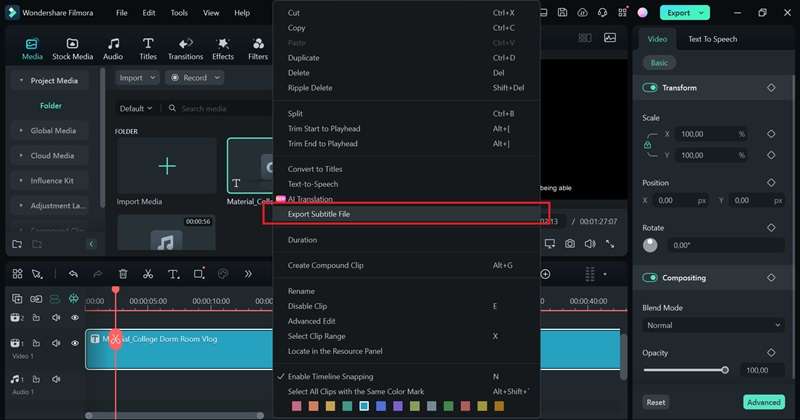
Passo 6:Salva o aggiunge la trascrizione al tuo progetto
Dopo aver effettuato tutte le modifiche necessarie, è possibile esportare la trascrizione come file srt. Fare clic con il pulsante destro del mouse sulla traccia di trascrizione del testo sulla timeline e selezionare "Esporta file sottotitolo.”
Le conclusioni
Apis libero di parola a testo aiutano gli sviluppatori a integrare la trascrizione nelle loro applicazioni senza sostenere costi elevati. Nell'articolo di oggi, abbiamo rivisto alcuni dei migliori strumenti sul mercato, tra cui Google Cloud speech-to-text, Microsoft Azure, Speechmatics, assembly, e aws transcribe. Che tu stia lavorando su piccoli progetti o testando il riconoscimento vocale per il tuo progetto, queste opzioni gratuite sono un solido punto di partenza.
Tuttavia, se stai cercando una soluzione più non tecnica, la funzione linguistica a testo integrata di Filmora può essere un'alternativa eccellente. Semplifica il processo, specialmente per i creatori di video o aziende che necessitano di trascrizione rapida senza la complessità delle integrazioni API.


